
richimanbtc式は死んだんだ
いくら呼んでも帰っては来ないんだ
もうあの時間は終わって、君も人生と向き合う時なんだ
【悲報】richmanbtc氏今年マイナス収支


聖杯はないんだなー(´;ω;`)ウッ…
所詮テクニカル指標なのでやっぱり幻想だったのかな。
個人的に限りなく聖杯は実需狙いのゴトー日のみ。
 web-lukes.info
web-lukes.infoTable of Contents
『botterのリアル』を読んでいきます。
richmanbtcのチュートリアルには前提として
- トレードの知識
- テクニカル指標の知識
- 仮想通貨の知識
- プログラミングの知識
- 機械学習の知識
- 取引所の知識
- サーバー設置の知識
- Dockerの知識
これぐらいはわかっているでしょう。というレベルで書かれているので内容についていけない人は多いとおもいます。(俺も、その一人)
初心者向けの解説もふまえてrichmanbtc氏のチュートリアルを一通りやっていこうとおもう。
機械学習とルールベースのトレードの違い
先にルールベースついて説明すると、
ルールベースはトレードの予約注文です。「新規注文タイミング」と「決済タイミング」をあらかじめ指定します。

ルールベースはテレビの毎週録画みたいなものですね。
例えば「前日から価格10%値下がりしたらBuy」「ポジション保有して3%値上げ、又は2%下落したらポジションクローズ」というカウンター予約注文をだしておくと、この通りに自動売買します。
では機械学習トレードは?
機械学習のトレードでは”おまかせ”が出来るようになります。
わたしは散髪にいくとき、いつも床屋さんに”おまかせ”しています。
richmanbtcさんは機械学習で”完全おまかせ”にするのではなく、
ルールベース+機械学習で戦略を練っています。
ルールベースのシグナルで、機械学習は審判の役割を果たします。
審判のレベルで勝率アップです。
チュートリアル初期値はチンパンジーレベルの審判かもしれません。
システムトレードやプログラミングがまったくわからない
そういう人は、先にMT4で自動売買を作ってみた方が良いです。
richmanbtc式はテクニカル指標を使った自動売買の延長線にあるので、元を辿るとMT4のEAでの自動売買です。
このブログでもMT4、MT5、TradingViewなどのプラットフォームサービスを使った簡単に作れる自動売買を紹介しています。
以下のリンクは1時間でさくっと作れる自動売買作成方法を紹介しています。
以下、動画でわかるTradingViewとPythonを使った自動売買作成方法です。
以下、テクニカル指標SMA(単純移動平均)を使った自動売買作成方法です。
以下、ドル円のアノマリーEAの作成方法です。
最近はFX業者でも仮想通貨自動売買(EAエキスパートアドバイザー)ができるようになってきた。

機械学習をトレードに応用する
本題はいります。
界隈で「仮想通貨の値動きをAIで予測するのは運ゲー」と言われてるみたい。
たしかに同じようなチャートでも上がったり下がったりランダムに動きますから、同じデータでもある時は上昇しある時は下落します。
他の機械学習のお題よりも攻略難易度が高い、ということは頭の片隅に置いといてください。
richmanbtc方式では15分ごとに指値をだして、実際に利益がでるかどうかを機械学習させることにしています。
richmanbtcチュートリアルの執行戦略
- 15分ごとに指値する
チュートリアルでは以下の順番でMLBOTをつくっていますので上からなぞっていきたいと思います。
- ヒストリカルデータのデータ取得
- 取引所手数料のデータ取得
- 特徴量の作成
- 目的変数の作成
- AIに学習させる
- バックテスト・検定
MLBOTの善し悪しは何でわかるの?
機械学習は汎化性能で良いか悪いかを判別するみたいです。
以下のサイトから引用します。
ここで機械学習モデルの性能とは、訓練データに対してではなく、未知の入力(テストデータ)に対して望ましい結果を返すことです。このような性能を、機械学習の分野では 汎化性能と呼びます。
機械学習がなんなのかをなんとなく理解してからやった方がいいかも。
EAの最適化とは違うの?
EAの最適化は数値を総当たりで入力して過去チャートにフィッティングさせています。
機械学習は数値を与えて訓練させて未来予測させます。
訓練方法は色々な方法があり、訓練方法をモデルとか手法とか呼びます。
線形回帰や決定木を使った方法があるみたいです。
線形回帰がよく分からない人はまず以下の動画がおすすめです。数式を使わずに説明してくれます。
線形回帰とは、説明変数に対して目的変数が線形またはそれから近い値で表される状態。 線形回帰は統計学における回帰分析の一種であり、非線形回帰と対比される。 また線形回帰のうち、説明変数が1つの場合を単純線形回帰、2つ以上の場合を重回帰と呼ばれる。 ウィキペディア
MLBOTをつくる
買い指値・売り指値の判定が必要なので判断するAIを2体つくります。
機械学習では (1).正解データ※ と (2).特徴量※ 2つのデータを与えると機械がパターンを見つけてくれます。
※(1).正解データ 答えとも目的変数とも呼ばれる正解の数値(ここでは取引結果)
※(2).特徴量 説明変数とも呼ばれる答えを導き出すトレードの判断材料(ここでは各テクニカル指標)
チュートリアルではまず、特徴量(トレード判断材料)を作ることから始めます。
MLBOTは特徴量というトレードの判断材料(ここではテクニカル指標の数値)を観てトレードするしないを判断します。
あなたがトレードする時はどこを見て売買を判断していますか?
多分チャートの値動きやテクニカル指標をみたりすると思います。
richmanbtc式のMLBOTはチャートの値動きを見ません。
そのタイミングのテクニカル指標の数値で売買を判断しています。
MLBOTに覚えさせる判断材料は、こちらで用意する必要があるのでPythonのテクニカル指標ライブラリのtalibを使います。
ライブラリをインストールしたらテクニカル指標を計算するために、ヒストリカルデータ(過去のローソク足データ)をダウンロードします。
ライブラリのインポート
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
import math import ccxt from crypto_data_fetcher.gmo import GmoFetcher import joblib import lightgbm as lgb import matplotlib.pyplot as plt import numba import numpy as np import pandas as pd from scipy.stats import ttest_1samp import seaborn as sns import talib from sklearn.ensemble import BaggingRegressor from sklearn.linear_model import RidgeCV from sklearn.model_selection import cross_val_score, KFold, TimeSeriesSplit |
Pythonに機能追加させます。
ライブラリの説明(アルファベット順)
- math 数学の計算
- crypto_data_fetcher.gmo ヒストリカルデータ取得
- joblib 並列処理
- lightgbm 機械学習
- matplotlib グラフ描画
- numba 計算の高速化
- numpy 計算
- pandas 表計算
- scipy 数値解析
- seaborn グラフ描画
- talib テクニカル指標
- sklearn 機械学習
ヒストリカルデータ取得(15分ローソク足過去データ)と表計算のデータに変換
|
1 2 3 4 5 6 7 8 9 10 11 12 |
memory = joblib.Memory('/tmp/gmo_fetcher_cache', verbose=0) fetcher = GmoFetcher(memory=memory) # GMOコインのBTC/JPYレバレッジ取引 ( https://api.coin.z.com/data/trades/BTC_JPY/ )を取得 # 初回ダウンロードは時間がかかる df = fetcher.fetch_ohlcv( market='BTC_JPY', # 市場のシンボルを指定 interval_sec=15 * 60, # 足の間隔を秒単位で指定。この場合は15分足 ) # 実験に使うデータ期間を限定する df = df[df.index < pd.to_datetime('2021-04-01 00:00:00Z')] display(df) df.to_pickle('df_ohlcv.pkl') |
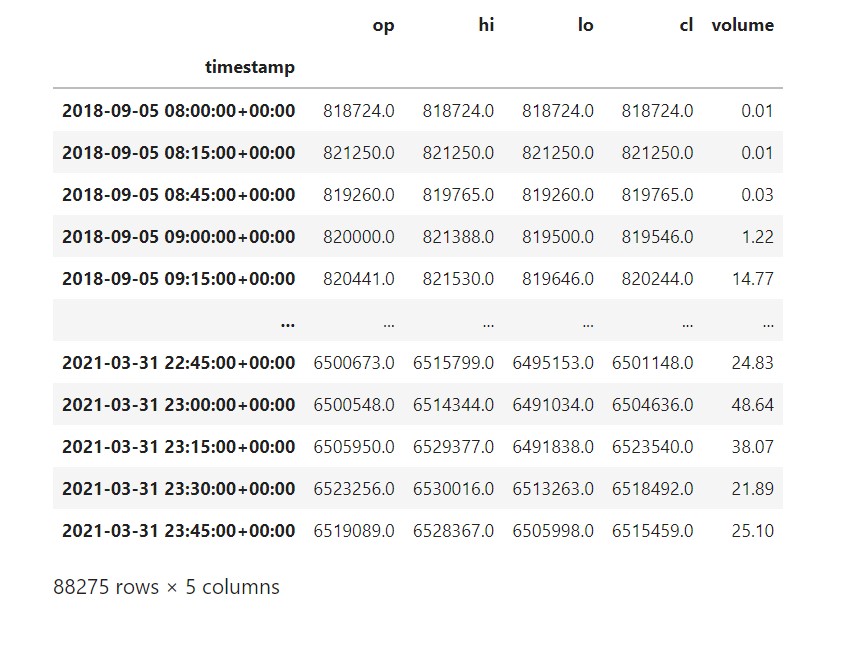
ヒストリカルデータが手に入りました。
ライブラリcrypto_data_fetcher.gmoを使ってヒストリカルデータを取得後、表計算ライブラリのpandas形式にした過去ローソク足のデータ表を作っています。
メイカー取引手数料の取得、取引手数料の列を表に追加
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
maker_fee_history = [ { # https://coin.z.com/jp/news/2020/08/6482/ # 変更時刻が記載されていないが、定期メンテナンス後と仮定 'changed_at': '2020/08/05 06:00:00Z', 'maker_fee': -0.00035 }, { # https://coin.z.com/jp/news/2020/08/6541/ 'changed_at': '2020/09/09 06:00:00Z', 'maker_fee': -0.00025 }, { # https://coin.z.com/jp/news/2020/10/6686/ 'changed_at': '2020/11/04 06:00:00Z', 'maker_fee': 0.0 }, ] df = pd.read_pickle('df_ohlcv.pkl') # 初期の手数料 # https://web.archive.org/web/20180930223704/https://coin.z.com/jp/corp/guide/fees/ df['fee'] = 0.0 for config in maker_fee_history: df.loc[pd.to_datetime(config['changed_at']) <= df.index, 'fee'] = config['maker_fee'] df['fee'].plot() plt.title('maker手数料の推移') plt.show() display(df) df.to_pickle('df_ohlcv_with_fee.pkl') |
GMOコインのメイカー手数料を取得しています。取得後、表に手数料の列[fee]を追加します。
GMOコインは手数料がマイナスなのでトレードするたびに利益が発生します。
これでローソク足のOHLCV(始値、高値、安値、終値、取引高)と取引所の取引手数料(fee)のデータが手に入りました。

特徴量(説明変数)の作成、テクニカル指標の列を追加
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 |
def calc_features(df): open = df['op'] high = df['hi'] low = df['lo'] close = df['cl'] volume = df['volume'] orig_columns = df.columns hilo = (df['hi'] + df['lo']) / 2 df['BBANDS_upperband'], df['BBANDS_middleband'], df['BBANDS_lowerband'] = talib.BBANDS(close, timeperiod=5, nbdevup=2, nbdevdn=2, matype=0) df['BBANDS_upperband'] -= hilo df['BBANDS_middleband'] -= hilo df['BBANDS_lowerband'] -= hilo df['DEMA'] = talib.DEMA(close, timeperiod=30) - hilo df['EMA'] = talib.EMA(close, timeperiod=30) - hilo df['HT_TRENDLINE'] = talib.HT_TRENDLINE(close) - hilo df['KAMA'] = talib.KAMA(close, timeperiod=30) - hilo df['MA'] = talib.MA(close, timeperiod=30, matype=0) - hilo df['MIDPOINT'] = talib.MIDPOINT(close, timeperiod=14) - hilo df['SMA'] = talib.SMA(close, timeperiod=30) - hilo df['T3'] = talib.T3(close, timeperiod=5, vfactor=0) - hilo df['TEMA'] = talib.TEMA(close, timeperiod=30) - hilo df['TRIMA'] = talib.TRIMA(close, timeperiod=30) - hilo df['WMA'] = talib.WMA(close, timeperiod=30) - hilo df['ADX'] = talib.ADX(high, low, close, timeperiod=14) df['ADXR'] = talib.ADXR(high, low, close, timeperiod=14) df['APO'] = talib.APO(close, fastperiod=12, slowperiod=26, matype=0) df['AROON_aroondown'], df['AROON_aroonup'] = talib.AROON(high, low, timeperiod=14) df['AROONOSC'] = talib.AROONOSC(high, low, timeperiod=14) df['BOP'] = talib.BOP(open, high, low, close) df['CCI'] = talib.CCI(high, low, close, timeperiod=14) df['DX'] = talib.DX(high, low, close, timeperiod=14) df['MACD_macd'], df['MACD_macdsignal'], df['MACD_macdhist'] = talib.MACD(close, fastperiod=12, slowperiod=26, signalperiod=9) # skip MACDEXT MACDFIX たぶん同じなので df['MFI'] = talib.MFI(high, low, close, volume, timeperiod=14) df['MINUS_DI'] = talib.MINUS_DI(high, low, close, timeperiod=14) df['MINUS_DM'] = talib.MINUS_DM(high, low, timeperiod=14) df['MOM'] = talib.MOM(close, timeperiod=10) df['PLUS_DI'] = talib.PLUS_DI(high, low, close, timeperiod=14) df['PLUS_DM'] = talib.PLUS_DM(high, low, timeperiod=14) df['RSI'] = talib.RSI(close, timeperiod=14) df['STOCH_slowk'], df['STOCH_slowd'] = talib.STOCH(high, low, close, fastk_period=5, slowk_period=3, slowk_matype=0, slowd_period=3, slowd_matype=0) df['STOCHF_fastk'], df['STOCHF_fastd'] = talib.STOCHF(high, low, close, fastk_period=5, fastd_period=3, fastd_matype=0) df['STOCHRSI_fastk'], df['STOCHRSI_fastd'] = talib.STOCHRSI(close, timeperiod=14, fastk_period=5, fastd_period=3, fastd_matype=0) df['TRIX'] = talib.TRIX(close, timeperiod=30) df['ULTOSC'] = talib.ULTOSC(high, low, close, timeperiod1=7, timeperiod2=14, timeperiod3=28) df['WILLR'] = talib.WILLR(high, low, close, timeperiod=14) df['AD'] = talib.AD(high, low, close, volume) df['ADOSC'] = talib.ADOSC(high, low, close, volume, fastperiod=3, slowperiod=10) df['OBV'] = talib.OBV(close, volume) df['ATR'] = talib.ATR(high, low, close, timeperiod=14) df['NATR'] = talib.NATR(high, low, close, timeperiod=14) df['TRANGE'] = talib.TRANGE(high, low, close) df['HT_DCPERIOD'] = talib.HT_DCPERIOD(close) df['HT_DCPHASE'] = talib.HT_DCPHASE(close) df['HT_PHASOR_inphase'], df['HT_PHASOR_quadrature'] = talib.HT_PHASOR(close) df['HT_SINE_sine'], df['HT_SINE_leadsine'] = talib.HT_SINE(close) df['HT_TRENDMODE'] = talib.HT_TRENDMODE(close) df['BETA'] = talib.BETA(high, low, timeperiod=5) df['CORREL'] = talib.CORREL(high, low, timeperiod=30) df['LINEARREG'] = talib.LINEARREG(close, timeperiod=14) - close df['LINEARREG_ANGLE'] = talib.LINEARREG_ANGLE(close, timeperiod=14) df['LINEARREG_INTERCEPT'] = talib.LINEARREG_INTERCEPT(close, timeperiod=14) - close df['LINEARREG_SLOPE'] = talib.LINEARREG_SLOPE(close, timeperiod=14) df['STDDEV'] = talib.STDDEV(close, timeperiod=5, nbdev=1) return df df = pd.read_pickle('df_ohlcv_with_fee.pkl') df = df.dropna() df = calc_features(df) display(df) df.to_pickle('df_features.pkl') |
PythonライブラリTA-Libを使ってテクニカル指標の列を作成しています。
特徴量には価格情報を含めないテクニカル指標を使います。
テクニカル指標の計算はご存知ですか?
例えばテクニカル指標の移動平均線は期間の平均を計算しています。
期間とはローソク足の本数です。
期間14の場合はローソク足14本。
ローソク足14の終値の平均価格が移動平均線の数値です。
richmanbtcチュートリアルでは価格情報を含まないテクニカル指標を採用して、時系列変化に強いBOTを作っています。
移動平均線なんかは価格がもろ反映されるので移動平均線というデータは使いません。
ボリンジャーバンドも移動平均線使っているのでボリンジャーバンドから価格情報を引いた数字を使っています。
これで特徴量が出来ました。使いたい特徴量を列から選びます。
特徴量は買いでも売りでも同じデータを使い回します。
このあとの特徴量の選択は省略します。
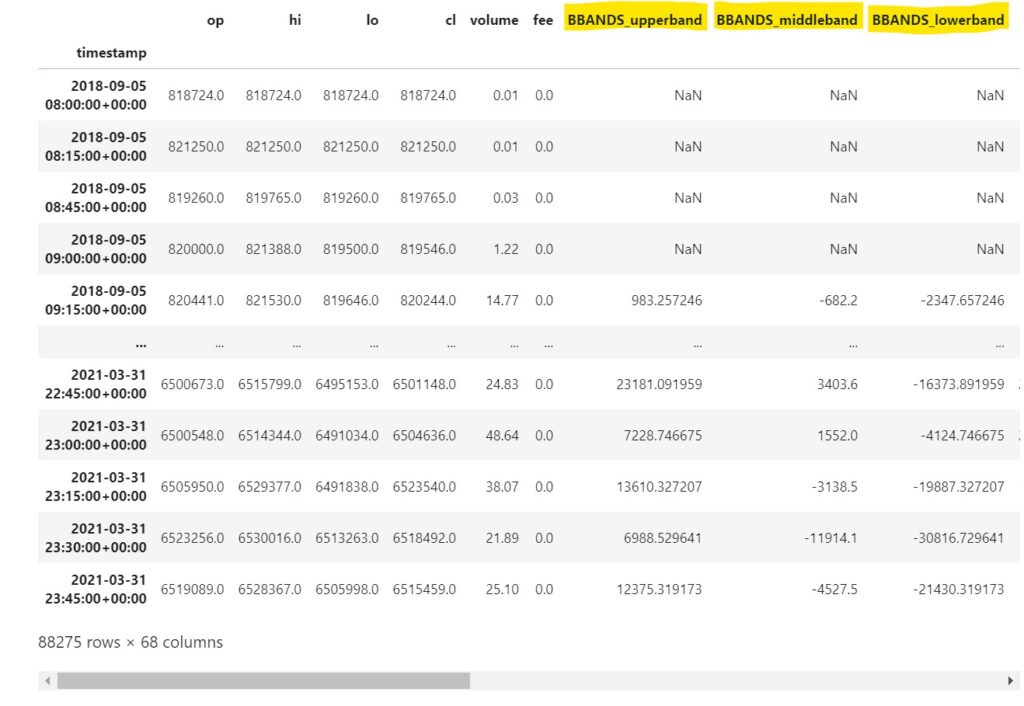
正解データ(目的変数)の作成、正解データの列を追加
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 |
@numba.njit def calc_force_entry_price(entry_price=None, lo=None, pips=None): y = entry_price.copy() y[:] = np.nan force_entry_time = entry_price.copy() force_entry_time[:] = np.nan for i in range(entry_price.size): for j in range(i + 1, entry_price.size): if round(lo[j] / pips) < round(entry_price[j - 1] / pips): y[i] = entry_price[j - 1] force_entry_time[i] = j - i break return y, force_entry_time df = pd.read_pickle('df_features.pkl') # 呼び値 (取引所、取引ペアごとに異なるので、適切に設定してください) pips = 1 # ATRで指値距離を計算します limit_price_dist = df['ATR'] * 0.5 limit_price_dist = np.maximum(1, (limit_price_dist / pips).round().fillna(1)) * pips # 終値から両側にlimit_price_distだけ離れたところに、買い指値と売り指値を出します df['buy_price'] = df['cl'] - limit_price_dist df['sell_price'] = df['cl'] + limit_price_dist # Force Entry Priceの計算 df['buy_fep'], df['buy_fet'] = calc_force_entry_price( entry_price=df['buy_price'].values, lo=df['lo'].values, pips=pips, ) # calc_force_entry_priceは入力と出力をマイナスにすれば売りに使えます df['sell_fep'], df['sell_fet'] = calc_force_entry_price( entry_price=-df['sell_price'].values, lo=-df['hi'].values, # 売りのときは高値 pips=pips, ) df['sell_fep'] *= -1 horizon = 1 # エントリーしてからエグジットを始めるまでの待ち時間 (1以上である必要がある) fee = df['fee'] # maker手数料 # 指値が約定したかどうか (0, 1) df['buy_executed'] = ((df['buy_price'] / pips).round() > (df['lo'].shift(-1) / pips).round()).astype('float64') df['sell_executed'] = ((df['sell_price'] / pips).round() < (df['hi'].shift(-1) / pips).round()).astype('float64') # yを計算 df['y_buy'] = np.where( df['buy_executed'], df['sell_fep'].shift(-horizon) / df['buy_price'] - 1 - 2 * fee, 0 ) df['y_sell'] = np.where( df['sell_executed'], -(df['buy_fep'].shift(-horizon) / df['sell_price'] - 1) - 2 * fee, 0 ) # バックテストで利用する取引コストを計算 df['buy_cost'] = np.where( df['buy_executed'], df['buy_price'] / df['cl'] - 1 + fee, 0 ) df['sell_cost'] = np.where( df['sell_executed'], -(df['sell_price'] / df['cl'] - 1) + fee, 0 ) print('約定確率を可視化。時期によって約定確率が大きく変わると良くない。') df['buy_executed'].rolling(1000).mean().plot(label='買い') df['sell_executed'].rolling(1000).mean().plot(label='売り') plt.title('約定確率の推移') plt.legend(bbox_to_anchor=(1.05, 1)) plt.show() print('エグジットまでの時間分布を可視化。長すぎるとロングしているだけとかショートしているだけになるので良くない。') df['buy_fet'].rolling(1000).mean().plot(label='買い') df['sell_fet'].rolling(1000).mean().plot(label='売り') plt.title('エグジットまでの平均時間推移') plt.legend(bbox_to_anchor=(1.2, 1)) plt.show() df['buy_fet'].hist(alpha=0.3, label='買い') df['sell_fet'].hist(alpha=0.3, label='売り') plt.title('エグジットまでの時間分布') plt.legend(bbox_to_anchor=(1.2, 1)) plt.show() print('毎時刻、この執行方法でトレードした場合の累積リターン') df['y_buy'].cumsum().plot(label='買い') df['y_sell'].cumsum().plot(label='売り') plt.title('累積リターン') plt.legend(bbox_to_anchor=(1.05, 1)) plt.show() df.to_pickle('df_y.pkl') |
答え(目的変数)には「指値が刺さったときの取引結果」を計算していきます。
トレードの結果(損益)を目的変数yにしています。
AI2体のため答えも2個(買い指値・売り指値)用意しましょう。
指値価格はテクニカル指標のATRを使って毎回計算しています。
買い指値価格 前ローソク足終値 – ATR * 0.5
売り指値価格 前ローソク足終値 + ATR * 0.5
例えば0時00分00秒に、23時45分のローソク足の終値からATRを使って計算した価格に買い指値をだします。
そのローソク足の安値が指値価格以下になれば指値→指値約定したことになります。
約定したポジションを今度は決済します。
決済もATRで計算した指値が刺さるまでローソク足が切り替わりに指値をだします。
指値が刺さったら1回の取引結果がわかるので、その取引結果を機械学習の正解データとします。
順番としては
指値価格計算
指値が刺さった約定価格(fep)を計算
そのローソク足でエントリーしたかどうかを計算
エントリーしたポジションの取引結果を計算
正解データは買いと売りように2つ用意します。
取引結果を正解データする。
- y_buy 買い指値の取引結果
- y_sell 売り指値の取引結果
正解データ(y_buy、y_sell)の列を表に追加します。
機械学習をする(特徴量と正解データをBOTに食べさせる)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
df = pd.read_pickle('df_y.pkl') df = df.dropna() # モデル (コメントアウトで他モデルも試してみてください) # model = RidgeCV(alphas=np.logspace(-7, 7, num=20)) model = lgb.LGBMRegressor(n_jobs=-1, random_state=1) # アンサンブル (コメントアウトを外して性能を比較してみてください) # model = BaggingRegressor(model, random_state=1, n_jobs=1) # 本番用モデルの学習 (このチュートリアルでは使わない) # 実稼働する用のモデルはデータ全体で学習させると良い model.fit(df[features], df['y_buy']) joblib.dump(model, 'model_y_buy.xz', compress=True) model.fit(df[features], df['y_sell']) joblib.dump(model, 'model_y_sell.xz', compress=True) # 通常のCV cv_indicies = list(KFold().split(df)) # ウォークフォワード法 # cv_indicies = list(TimeSeriesSplit().split(df)) # OOS予測値を計算 def my_cross_val_predict(estimator, X, y=None, cv=None): y_pred = y.copy() y_pred[:] = np.nan for train_idx, val_idx in cv: estimator.fit(X[train_idx], y[train_idx]) y_pred[val_idx] = estimator.predict(X[val_idx]) return y_pred df['y_pred_buy'] = my_cross_val_predict(model, df[features].values, df['y_buy'].values, cv=cv_indicies) df['y_pred_sell'] = my_cross_val_predict(model, df[features].values, df['y_sell'].values, cv=cv_indicies) # 予測値が無い(nan)行をドロップ df = df.dropna() print('毎時刻、y_predがプラスのときだけトレードした場合の累積リターン') df[df['y_pred_buy'] > 0]['y_buy'].cumsum().plot(label='買い') df[df['y_pred_sell'] > 0]['y_sell'].cumsum().plot(label='売り') (df['y_buy'] * (df['y_pred_buy'] > 0) + df['y_sell'] * (df['y_pred_sell'] > 0)).cumsum().plot(label='買い+売り') plt.title('累積リターン') plt.legend(bbox_to_anchor=(1.05, 1)) plt.show() df.to_pickle('df_fit.pkl') |
機械学習のプログラミングはライブラリを使うとシンプルに実装できます。
本番用の分類器model_y_buy.xz、model_y_sell.xzを払い出してます。
バックテスト用はクロスバリデーションでオーバーフィッティングを避けます。
クロスバリデーション難しいので下記Youtubeの動画視聴推奨です。
特徴量(各テクニカル指標)と正解データ(y_buy、y_sell)が出来たのでこの二つをモデル(機械学習の手法)に与えることで、機械学習を行ってくれます。
model BOTに覚えさせる方法
model.fit BOTに特徴量、正解データを与え覚えさせる
そうすると学習済みモデル(特徴量で判断するボットの頭脳)が完成するので、学習済みモデルに予測させます。
y_pred_buy 買い予測結果
y_pred_sell 買い予測結果
学習モデルが特徴量を読み取って、この特徴量ならリターンがプラスになる(利益がでる)と予測をだしたときに指値を実行させます。
チュートリアルのBOTは予測精度がそこまで高くありません。
なので予測有り、予測無しでもあまりリターン結果のグラフは見た目かわらないです。
クロスバリデーションについては説明が難しいので機械学習で株価予測する以下ののYoutubeが参考になります。
バックテストとp検定
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 |
@numba.njit def backtest(cl=None, hi=None, lo=None, pips=None, buy_entry=None, sell_entry=None, buy_cost=None, sell_cost=None ): n = cl.size y = cl.copy() * 0.0 poss = cl.copy() * 0.0 ret = 0.0 pos = 0.0 for i in range(n): prev_pos = pos # exit if buy_cost[i]: vol = np.maximum(0, -prev_pos) ret -= buy_cost[i] * vol pos += vol if sell_cost[i]: vol = np.maximum(0, prev_pos) ret -= sell_cost[i] * vol pos -= vol # entry if buy_entry[i] and buy_cost[i]: vol = np.minimum(1.0, 1 - prev_pos) * buy_entry[i] ret -= buy_cost[i] * vol pos += vol if sell_entry[i] and sell_cost[i]: vol = np.minimum(1.0, prev_pos + 1) * sell_entry[i] ret -= sell_cost[i] * vol pos -= vol if i + 1 < n: ret += pos * (cl[i + 1] / cl[i] - 1) y[i] = ret poss[i] = pos return y, poss df = pd.read_pickle('df_fit.pkl') # バックテストで累積リターンと、ポジションを計算 df['cum_ret'], df['poss'] = backtest( cl=df['cl'].values, buy_entry=df['y_pred_buy'].values > 0, sell_entry=df['y_pred_sell'].values > 0, buy_cost=df['buy_cost'].values, sell_cost=df['sell_cost'].values, ) df['cum_ret'].plot() plt.title('累積リターン') plt.show() print('ポジション推移です。変動が細かすぎて青色一色になっていると思います。') print('ちゃんと全ての期間でトレードが発生しているので、正常です。') df['poss'].plot() plt.title('ポジション推移') plt.show() print('ポジションの平均の推移です。どちらかに偏りすぎていないかなどを確認できます。') df['poss'].rolling(1000).mean().plot() plt.title('ポジション平均の推移') plt.show() print('取引量(ポジション差分の絶対値)の累積です。') print('期間によらず傾きがだいたい同じなので、全ての期間でちゃんとトレードが行われていることがわかります。') df['poss'].diff(1).abs().dropna().cumsum().plot() plt.title('取引量の累積') plt.show() print('t検定') x = df['cum_ret'].diff(1).dropna() t, p = ttest_1samp(x, 0) print('t値 {}'.format(t)) print('p値 {}'.format(p)) # p平均法 https://note.com/btcml/n/n0d9575882640 def calc_p_mean(x, n): ps = [] for i in range(n): x2 = x[i * x.size // n:(i + 1) * x.size // n] if np.std(x2) == 0: ps.append(1) else: t, p = ttest_1samp(x2, 0) if t > 0: ps.append(p) else: ps.append(1) return np.mean(ps) def calc_p_mean_type1_error_rate(p_mean, n): return (p_mean * n) ** n / math.factorial(n) x = df['cum_ret'].diff(1).dropna() p_mean_n = 5 p_mean = calc_p_mean(x, p_mean_n) print('p平均法 n = {}'.format(p_mean_n)) print('p平均 {}'.format(p_mean)) print('エラー率 {}'.format(calc_p_mean_type1_error_rate(p_mean, p_mean_n))) |
バックテストは過去のチャートで実際にポジションをとった場合どうなるかを確認しています。
コードの意味はつかまなくてよいかも。雰囲気でOKです。
いま(2022/05/20)はBacktesting.pyというライブラリを使った方がいいかもしれないです。
p検定は今後も使えるかどうか(安定的に威力を発揮するか)を確認しています。
バックテストでは
- 買いAIに特徴量から予測させた数値がプラスだったら、買い
- 売りAIに特徴量から予測させた数値がプラスだったら、売り
決済は予測にかかわらず、ATRで計算したところにローソク足毎指値をだしています。
バックテストは難しいので図解しました。
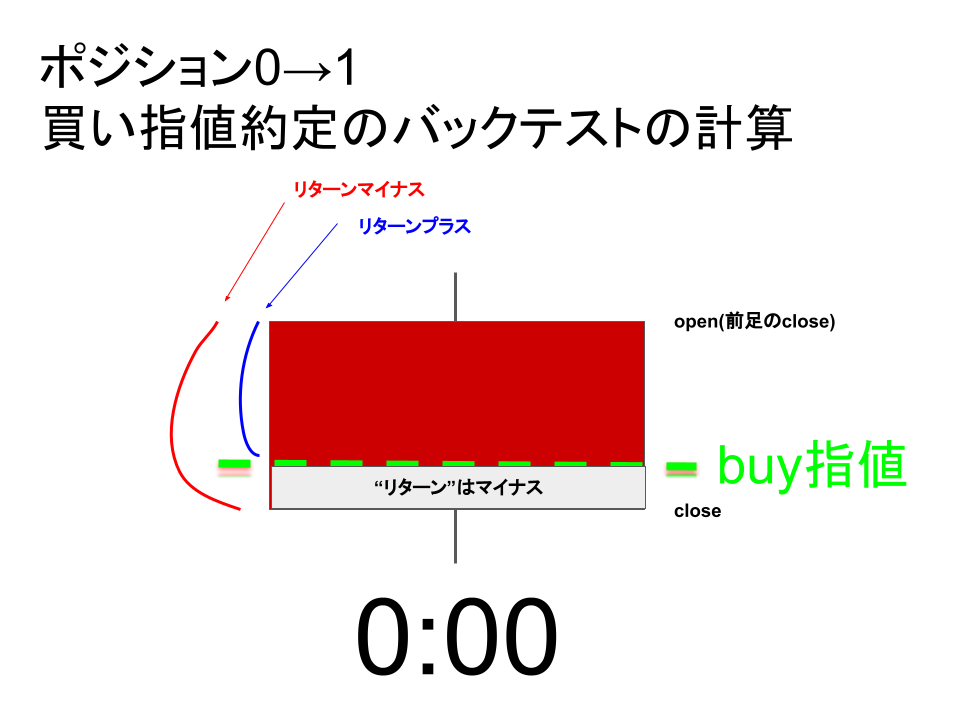
バックテストで利用する取引コストを計算
コストの計算おさらい
np.where(条件式,trueの場合,falseの場合) で指値約定した場合の一回のコストを計算(青色の部分)
df[‘buy_cost’] = np.where(df[‘buy_executed’],df[‘buy_price’] / df[‘cl’] – 1 + fee,0)
df[‘buy_price’]は指値価格。現在の足の 終値 – ATR * 0.5
df[‘buy_executed’]は指値が刺さったかどうか。一個先の安値で計算。計算式には df[‘lo’].shift(-1) を使う。
df[‘buy_executed’],df[‘buy_price’] / df[‘cl’] – 1
-1しているのでbuy_cost[i] (コスト)は全てマイナスの数字になる
バックテストでは、その行に「コストが含まれている場合かつポジションを保有している場合」に以下の計算でリターンにプラスしている。
ret -= buy_cost[i] * vol
buy_cost[i]マイナスの数字なのでリターンからマイナスするとプラスになる。
– buy_cost[i]
-買い指値コスト(マイナスの数字)
バックテストのclose計算に使う価格は
cl[i] #一個先の始値(open)
cl[i + 1] #一個先の終値(close)
つまり、すべて一個先の計算をしている。
- buy_price[i] #一個先に出す指値価格
- lo[i+1] #一個先の安値(lo)
- cl[i] #一個先の始値(open)
- cl[i + 1] #一個先の終値(close)
頭ごちゃごちゃしているかと思いますが、図の通りです。
以上でチュートリアル部分おわりです。
初期値のBOTの審判精度は高くないのでこっからどんどんパワーアップさせたいです。
ここまでやって初めてスタートラインです。

参考になるブログ・記事
理解するのが難しいと思うので助けになる記事を張っておきます。上から3つは無料で読めて、ADAMさんのは有料noteです。



機械学習おすすめ本の紹介
難易度が低い順番でおすすめしてきます。すべて目は通してあります(読み切ってはいない)
この本が体系的にまとまってておすすめ。Pythonの復習にも◎
難易度低いので3時間ぐらいで読める本。初心者向け。
ここから中級者向けです。
Pythonを理解してるなら、この本がおすすめ。
ルールベースのバックテスト方法が丁寧に解説されています。
内容は為替がメインで実際に動くBOTをつくってます。
説明不要!
まだいそぐ必要はないかも。(パラっとめくっただけ)
ここから上級者向け。
俺は無理だった
全章通して1ミリもわからない
異次元の難易度。
ポーカーでは勝率期待度でベット額を変えるらしい。
筆者の知見が増えたら更新します。
特徴量という宝探し
チュートリアルが終わったら次は実際にMLBOTを開発してみたいと思います。
そのあとは特徴量を探します。
なにかヒントがあればいいんですが…
そういえば機械学習のkaggleコンペで株価予測が開催されているみたい。
もしかしたらヒントが見つかるかも

上位入賞者の解法はrichmanbtc式に似てる要素があるみたいですね。
一旦テクニカル指標を全て使い予測精度に悪影響及ぼす特徴量を削除、テクニカル指標の相関を調べているとのことです。

次はMLBOT作って、機械学習株式分析チュートリアルやります。
みんなも一緒にやろう。
分類問題の方が良いかも



BybitがGoogleのIPアドレス規制をしているためです。国内のVPSなら使…
自分のbotで使ってるAPIキーを使用しているんですが、 You have br…
pybit 最新版にコードを変更しました。コードとrequirements.tx…
お返事ありがとうございます。はい。pybit==2.3.0になっております。
コードはあっていると思います。rewuirements.txtは「pybit==…